虽然加密技术新辈多出,但哈希算法(也称“散列算法”)自诞生以来,已成为加密算法领域不可或缺的应用。
最简单的散列算法也被用来加密存在数据库中的密码字符串,日常我们在各大APP中注册时填写的密码均是以字符串方式保存在服务器中,用户登陆时需要再次对输入密码实施哈希计算,而后将两个密码字符串进行碰撞验证登陆。
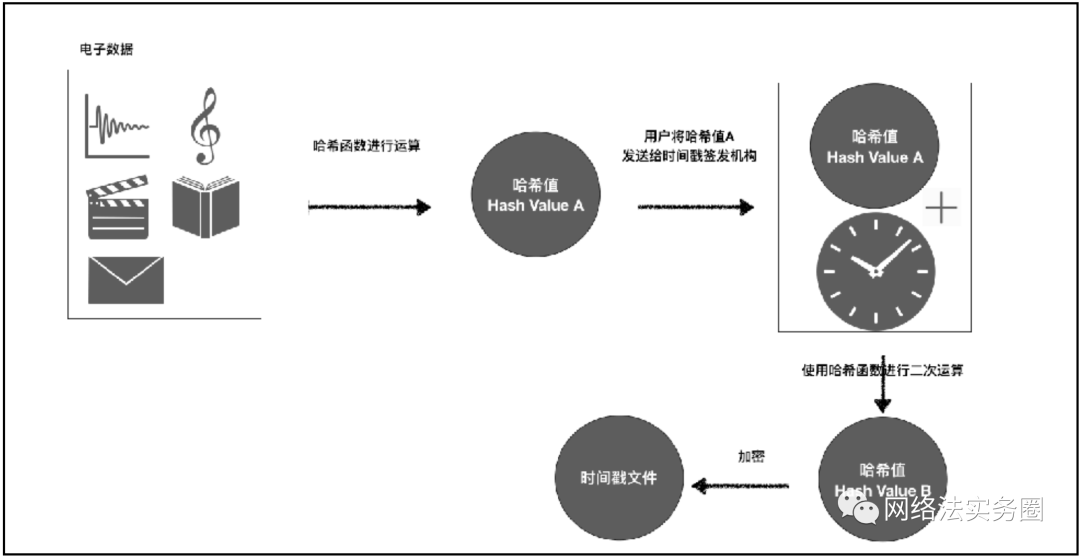
由于散列算法所计算出来的散列值(Hash Value)具有不可逆(无法逆向演算回原本的数值),以及其不可单方篡改(任一原始数据的变动,均会得出完全不同的散列值)的洁癖性质,哈希算法可以在一定程序上保护密码等数据。
除了上述用户密码以哈希算法方式进行保护,哈希算法在企业的数据保护工作中充当了急先锋的重要角色,有着广泛的应用。例如,企业的产品或服务在营销渠道(如各类DMP平台)投放品牌广告时,可能需要将其收集用户的手机号等数据实施哈希加密,并和营销渠道进行数据对碰,以此识别人群包中的交叉用户,最终实施精准信息流推送。这实质上也是一种数据的联合建模方式,虽然看似数据不出库,但实际上在相关场景及合意下,企业仍然可以通过对撞方式为己方用户生成和添附新的画像标签,这本质上仍然是一种数据收集/共享行为。也正是基于这些痛点,越来越多的企业开始寻求更复杂更安全的隐私计算路径。
在哈希函数应用中,企业最重要的是需要评估用户数据被“散列算法”后被重新识别的难易程度,以确定他们需要根据法律法规采取哪些进一步措施来保护用户数据的安全性,并避免自己陷入散列算法数据属于匿名化数据的错觉。
Knuddels案是德国首例GDPR处罚案件,该起案件就是企业未有效评估用户密码哈希值安全的最佳例子。2018年夏天,黑客攻击了Knuddels.de平台,导致约有808,000封电子邮件地址和180多万个用户名和密码被曝光。德国数据保护当局调查显示,Knuddels.de平台通过哈希方式加密存储了用户的密码,但同时把非哈希版本的明文账号密码也保留在了网络服务器上。德国数据保护当局认为,GDPR第32条要求数据控制者和处理者应当采取适当的技术和组织措施保证安全与风险一致性,包括要对个人数据进行假名化和加密处理,但显然Knuddels没有意识到密码哈希的保护方式。
哈希函数一直被用作保护个人数据的工具,但用户一直怀疑在何种情况下,散列是否可以真正将用户数据假名化甚至完全匿名化。这个问题很重要,因为个人信息保护法不适用于真正匿名的数据。欧盟《通用数据保护条例》也承认假化名是帮助企业履行数据安全义务的一种选择。
事实上,根据我国个人信息安全规范等行业逻辑,哈希函数后的哈希值本质上属于去标识化方式而不是匿名化技术。但笔者认为还是需要分场景考虑,常见的例如手机号码或身份证号进行哈希运算就是非常容易被攻破并重识别明文数据的,毕竟黑白客世界都有一个“彩虹表”的传奇存在。另外,不断发展壮大的社工库也让人们的隐私无所遁形,这些都是在声称有良好哈希加密的情况下被明文复原的方式。同时,哈希值本身就是用户新的唯一标识符,在实施数据关联后又是一条“好汉”。
但在特殊的极特例数据场景中,外部取得哈希函数值,甚至以多次哈希加密方式情况下取得数据的一方,在无源数据库支持下,是无法复原源数据的,则此数据仍然是有可能被认定为匿名数据的。到底是去标识化还是匿名化,虽然原则上仍应当以去标识化进行识别,但特殊场景中仍然可以个案判断为匿名化,不宜绝对化定义。
如上所述,可重识别性是企业合规评估的重中之重,不算是企业内部,还是对外提供或委托处理等数据流转场景中。为防止重新识别散列信息,在《INTRODUCTION TO THE HASH FUNCTION AS A PERSONAL DATA PSEUDONYMISATION TECHNIQU》(《散列函数作为个人数据假名化技术》)报告中,欧盟EDPS 和 AEPD 建议使用机密密钥对初始消息或散列值进行加密,或者使用称为“盐”的常数值或随机值进行加密,在创建哈希之前添加到所有原始消息中。
根据 上述报告,一系列因素会影响散列是否能够充分保护个人数据。在寻求应用该措施时,企业需要考虑到的因素包括:(1)散列的计算,使用的散列技术、算法和系统;(2)消息空间:熵――数据集中有序或无序的程度――如果添加随机元素,则消息的冗余和重复结构;(3)处理环境中散列与其他信息之间的联系:标识符或伪标识符是否与散列信息直接相关,或者信息是否与散列信息间接相关;(3)已经引入的密码和其他随机元素;(4)密码的持续管理和审计,包括物理安全和人为因素。
在常见的实践中,我们不能被口语表述中的“匿名化”所晃倒。
在“剑桥分析公司数据泄露”事件中,Facebook上超过5000万用户的信息被一家名为“Cambridge Analytica”的公司不当获取并用于未经授权的目的。然而,根据Facebook的解释,这些个人信息,例如用户填写的心理测试结果,全部是在经过“匿名化”处理后才被用于对外分享的。公司表示,在获取用户的授权后,这些数据会“通过匿名的方式被使用和分发,并且保证即使利用这些信息也不能追溯到个人用户”。
2006年,Netflix为改善其电影推荐服务,公布了包含部分用户评分的数据库,其中包括用户对电影的评分和评分日期。该数据库是匿名的,采用随机更改数据库中包含的大约480,000个用户的部分评级和评级日期等方法对数据库进行匿名化处理。但研究表明,只需非常少的辅助信息,就可以对Netflix数据库中的大部分的用户记录进行去匿名化。通过8部电影的评分,和允许误差14天的评分日期,就可以唯一标识数据库中99%的用户。
在基于哈希函数所提供服务产品的案例中,当年的Facebook(即现在的Meta元宇宙)自定义客户广告模式案例是值得研究的。自定义广告受众是一种较为直接主动的Facebook广告方式,通过这种方式,卖家不需要被未知的受众信息所局限,可以根据已有客户的Facebook 账号、邮箱地址或者电话建立特定目标受众,制定多元的广告格式,向更加精准的目标用户投放广告,提高广告投放效果。
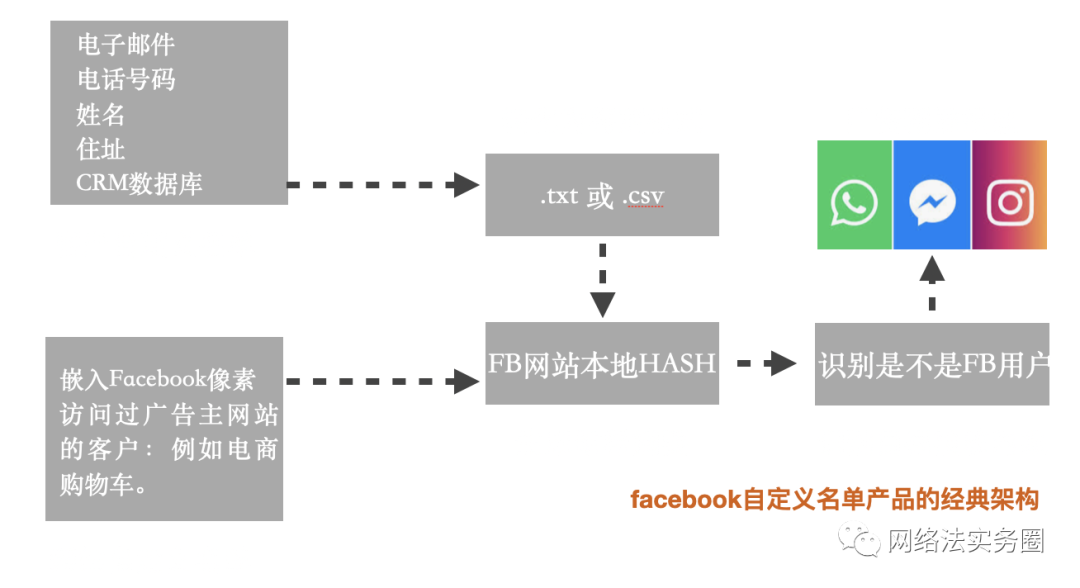 但是,德国巴伐利亚数据保护监督局BayLDA认为Facebook的自定义客户广告模式并不合法,要求在德国境内的网站所有者(一家网上商店的运营商)删除从他的Facebook帐户创建的用户列表。慕尼黑高级行政法院VGH 也指出,数据的哈希不能完全消除个人引用和可识别性。
但是,德国巴伐利亚数据保护监督局BayLDA认为Facebook的自定义客户广告模式并不合法,要求在德国境内的网站所有者(一家网上商店的运营商)删除从他的Facebook帐户创建的用户列表。慕尼黑高级行政法院VGH 也指出,数据的哈希不能完全消除个人引用和可识别性。
从上述案件可知,尽管使用了散列过程,但传输的数据至少对Facebook来说是个人的,理论上讲,Facebook可以将上传的CRM数据与其自身系统中的数据进行比较,从而明确地将提供的数据分配给特定的Facebook用户,哈希值仅阻止第三方重新识别。
当然,我们也需要考虑一个问题,虽然个人信息保护法不适用于匿名化数据,但对个人信息进行匿名化这一处理行为是否仍应当适用类如知情同意的规则,也是处于模糊地带。英国ICO(信息专员办公室)也曾就这个问题在其《anonymisation code》指引中明确表明了立场:匿名化过程通常不需要征得同意,获得同意可能非常麻烦,甚至是不可能的。但是问题也在于,如果采取的措施不能被视为是匿名化方式或技术,例如仅仅只是去标识化,则仍应当取得用户的同意为前提,这就为匿名化提出了实质性要求,避免将非匿名化技术认定为匿名化方法,不然会很尴尬。
很赞哦! (119)

 网盾网络安全培训学校,课程内容紧跟互联网安全技术发展与企业实际用人需求,不断升级更新。
学员可以深入接触web安全基础、漏洞分析、安全测试、渗透测试等全栈解决方案,掌握网络安全分析及解决方案,成长为真正的网络安全人才。
网盾网络安全培训学校,课程内容紧跟互联网安全技术发展与企业实际用人需求,不断升级更新。
学员可以深入接触web安全基础、漏洞分析、安全测试、渗透测试等全栈解决方案,掌握网络安全分析及解决方案,成长为真正的网络安全人才。