信息收集在攻击和防御两端都是非常重要的一环。从宏观的角度来说,大多数信息相关的工作都可以看作信息收集和信息处理交替进行的循环。优质的信息收集成果是后续工作顺利展开的首要条件。《孙子兵法》有云:故善战人之势,如转圆石于千仞之山者,势也。在掌握了充足信息后,攻防工作将“如转圆石于千仞之山”。
然而,信息的琐碎性和云原生本身的复杂组成为云原生环境下的信息收集工作带来了一定挑战。有些朋友也许会说,这有何难?比如,执行uname -a命令,就能收集到内核信息了。没错,信息收集确实是一步步进行、一项项完成的。但是,如果只是想当然地进行,收集到的信息难免陷于凌乱琐碎,也很可能不全面。
对此,笔者结合在攻、防两端积累的经验,希望与大家探讨四个问题:
就“信息收集”这个话题而言,毫无疑问,防守者是占尽天时地利的,无论是能够收集到的信息种类、规模,还是信息收集开始的时间、收集信息所需的权限,都远远在攻击者之上。防守者更需要关注的是如何使用、分析收集到的信息。因此,我们从攻击者的角度出发进行探讨。这并不意味着防守的同学不需要关注。相反,只有对攻击者的技术了然于胸,才能更好地识别攻击行为、判定攻击意图。
本系列第一篇文章讨论了云原生环境下的收集信息方式,给出“通过远程交互收集信息”、“在容器内收集信息”和“基于镜像收集信息”三种思路。作为本系列的第二篇文章,本文将讨论第二个问题:站在攻击者视角,云原生环境下的信息分类维度有哪些?
注:文中案例相关操作均在实验环境中进行,相关技术仅供研究交流,请勿应用于未授权的渗透测试。
我们会结合实践从信息收集的“广度与深度”、“软件栈层次”和“特定需求”三个方面来介绍云原生环境下的信息分类维度和体系化的收集思路,其中:
1 信息收集的广度与深度
信息的收集与分类离不开资产,脱离资产空谈信息收集是没有实际意义的。除了扮演攻击者角色的渗透测试同学,从事安全防御和网络空间测绘的同学也都十分重视资产。对于前者来说,有效防御的前提是确保重要资产都处于安全系统和安全管理流程的覆盖范围内,在此基础上不断监控资产状态、收集资产信息,对异常状态和行为进行分析、预警和处置;对于后者来说,测绘能力一定程度上等同于对资产信息的收集分析能力。
站在攻击者的角度,我们也可以将信息关联到资产上,从而将信息分类问题转化为资产分类问题。通常情况下,攻击者不像防守者(尤其是入侵检测系统、EDR等)那样拥有近乎上帝视角下的信息收集能力,却要比网络空间测绘以外在暴露特征为主的信息收集工作更主动、更有力。攻击者能够、且有必要去挖掘纵深渗透过程中接触到的每一个信息的可利用性。基于这些观察,我们将云原生环境中处于不同层次上的集群、主机、容器、进程及文件都定义为资产,并提出以下两个观点:
在以上两个观点的基础上,我们可以制作出面向资产的信息收集结构树:
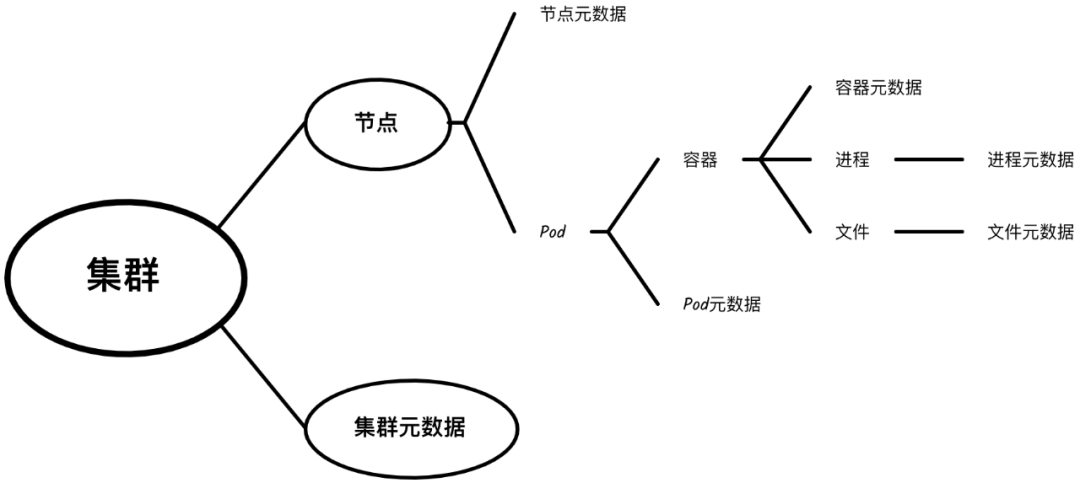
这棵树是我们在面对云原生集群目标时制定信息收集策略的好帮手,其中:
通过建立广度和深度的概念,我们总结出云原生环境中的资产关系,并绘制出信息收集结构树。这确实能够帮助我们把握信息收集的方向,但依然有些抽象,不能有效指导具体收集工作。接下来,我们将把这棵树具体化――结合实例来分享如何层次化收集云原生环境的信息。
2 信息收集的软件栈层次
将上一节的信息收集结构树展开,可以获得下面这样的信息收集矩阵:

其中,集群处于最高层次,覆盖的信息采集点最多;容器是最低层次,覆盖自身元数据和进程、文件的元数据。进程和文件作为叶子结点资产,不可再分,没有独立划出来。与ATT&CK矩阵类似,上图列出了常用的信息采集点,但信息收集矩阵本身在不同的软件栈层次上都是持续增长的。随着软件的更迭和技术的发展,失去价值的信息采集点可能会弃用,新的信息采集点可能会出现。
前面提到,没有上帝视角的攻击者能够收集到的信息注定是有限的。因此,我们必须充分利用收集到的信息,为目标集群画像,在黑盒状态下建立威胁模型,并尽可能不断完善这个模型。有的朋友可能会问:又是树,又是矩阵,到底有什么用呢?我们将在第三篇文章中详细讲述收集到的云原生环境信息的利用价值。在此之前,大家可以通过下面这幅测试环境下的实践图先睹为快:
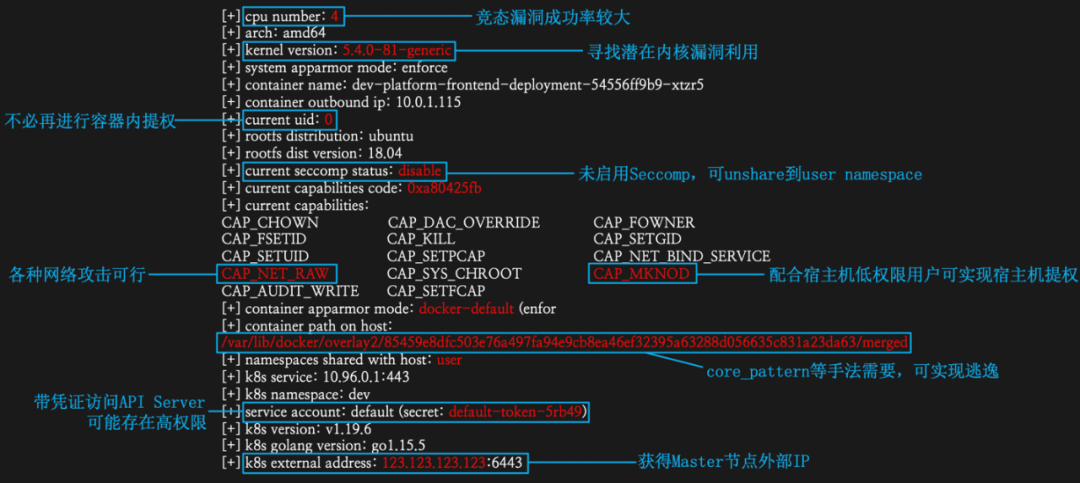
上图是我们对目标云原生环境应用信息收集矩阵的部分输出结果。可以看到,我们能够利用信息收集矩阵获取相当多的有价值信息,为后续的渗透测试指出方向。这些信息均采用本系列第一篇文章[2]中介绍的方法收集。下面,我们以检测命名空间共享情况为例来讲解具体的收集过程。
Linux Namespaces机制是构成容器的技术基石,包括不同类型的命名空间,实现对不同类型资源的隔离。判断容器是否与宿主机共享命名空间的关键是找到在攻击者信息收集能力范围内的共享与不共享两种情况之间的差异点。接下来,我们将介绍PID、Network命名空间的判断方法。
对于PID namespace来说,一种简单但不太精确的方法是观察/proc目录下的进程数。通常来说,宿主机上的进程要大大多于普通容器内的进程,进程执行的命令行(/proc/[PID]/cmdline)也种类各异。根据这些情况,人类也许很容易给出倾向性的判定,但却很难由机器自动化。我们的方法是读取/proc/sys/kernel/cad_pid的值,1表明是宿主机的PID命名空间,0则代表容器的独立PID命名空间:
rambo@t-matrix:~# docker run --rm-it ubuntu cat /proc/sys/kernel/cad_pid0rambo@t-matrix:~# docker run --rm -it --pid=hostubuntu cat /proc/sys/kernel/cad_pid1
根据内核文档[3],这个文件的值表示系统重启时接收Ctrl-Alt-Delete信号的进程的PID。可以发现,在宿主机上该值为1,在容器内该值为0。
对于Network namespace来说,可以通过检查容器的/etc/hosts文件是否有容器内部IP来判断。如下面的命令行操作所示,在共享宿主机Network namespace的情况下,容器内的/etc/hosts中没有172.17.0.2的内部IP:
rambo@t-matrix:~# docker run --rm-it --net=host centos:latest cat /etc/hosts127.0.0.1 localhost.localdomain localhost::1 localhost6.localdomain6localhost6 # The following lines are desirable for IPv6 capablehosts::1 localhost ip6-localhost ip6-loopbackfe00::0 ip6-localnetff02::1 ip6-allnodesff02::2 ip6-allroutersff02::3 ip6-allhostsrambo@t-matrix:~# docker run --rm -it centos:latestcat /etc/hosts127.0.0.1 localhost::1 localhostip6-localhost ip6-loopbackfe00::0 ip6-localnetff00::0 ip6-mcastprefixff02::1 ip6-allnodesff02::2 ip6-allrouters172.17.0.2 890791c776de
然而,在一些较为复杂的网络环境(如存在多种CNI插件可供选择的Kubernetes集群环境)中,这种方法也不够准确直观。因此,一种更好的方式是通过检查容器内的/proc/net/unix文件内容[4]来判断:
rambo@t-matrix:~# docker run --rm-it --net=host centos:latest grep "systemd" /proc/net/unix0000000000000000: 00000002 00000000 00000000 0002 014397653 /run/user/1000/systemd/notify...rambo@t-matrix:~# docker run --rm -it centos:latestgrep "systemd" /proc/net/unixrambo@t-matrix:~#
除了上面这种隔离性判定问题外,信息收集矩阵中的大部分信息都可以通过直接读取特定文件或发起特定网络访问的方式获得,思路一致,手法大同小异,不再展开讲解。
3面向特定需求收集信息
理论上,全面、体系化的信息收集工作确实能够最大程度地帮助我们感知目标环境,但在实践中也存在明显不足:容易触发告警。前文提到,防守的同学可以利用这一点“识别攻击行为、判定攻击意图”,正是如此。
因此,另一种思路便是面向特定需求收集信息,够用即可,点到为止。在下一篇文章中,我们会对云原生环境信息的利用价值进行总结。换个角度,利用价值也正是利用目的,无外数据泄露、权限提升、容器逃逸、横向移动四种:
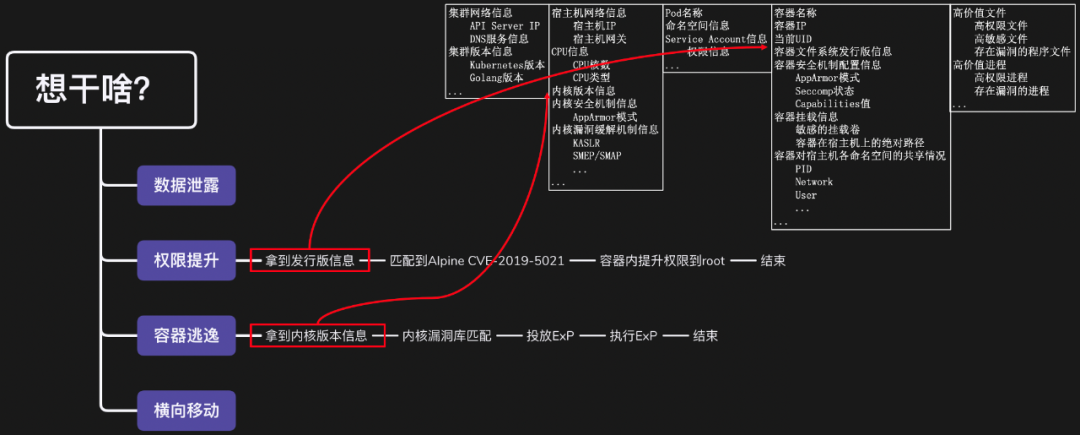
正如上图所展示的一样,如果明确了目的,那么实际执行的操作可能只是整个信息收集矩阵中很小的子集。
本文是“深入浅出云原生环境信息收集技术”系列的第二篇,分享了信息收集的广度深度和软件栈层次,并依次提出了信息收集结构树和信息收集矩阵,从抽象到具体一步步展开云原生环境信息收集工作,最后介绍了从需求出发的收集思路,作为体系化收集思路的补充。
在本系列开头[2],我们曾提出一个观点:大多数信息相关的工作都可以看作信息收集和信息处理交替进行的循环。希望大家能够通过本文感受到信息收集工作的魅力。现在,有了信息收集的方式,也有了信息分类的维度,下一篇文章将分享云原生环境信息的具体利用案例,达到“转圆石于千仞之山”的利用效果。
最后,向大家推荐由绿盟科技星云实验室编写的《云原生安全:攻防实践与体系构建》一书,本书系统梳理云原生安全可能面临的威胁与风险,给出切实可行的防护方案,随书附带丰富的配套实验。云原生从业者以及对云原生安全感兴趣的同学一定不要错过!

参考文献
[1] https://www.bilibili.com/video/BV1pL4y1g7FP
[2] https://mp.weixin.qq.com/s/qCfH80BWOTTOA707wVSY-w
[3] https://www.kernel.org/doc/html/latest/admin-guide/sysctl/kernel.html#cad-pid
[4] https://man7.org/linux/man-pages/man5/proc.5.html
很赞哦! (119)

 网盾网络安全培训学校,课程内容紧跟互联网安全技术发展与企业实际用人需求,不断升级更新。
学员可以深入接触web安全基础、漏洞分析、安全测试、渗透测试等全栈解决方案,掌握网络安全分析及解决方案,成长为真正的网络安全人才。
网盾网络安全培训学校,课程内容紧跟互联网安全技术发展与企业实际用人需求,不断升级更新。
学员可以深入接触web安全基础、漏洞分析、安全测试、渗透测试等全栈解决方案,掌握网络安全分析及解决方案,成长为真正的网络安全人才。