Javascript流行已久,V8引擎更是让其进化为服务端开发语言的一员。其对应的包管理工具NPM中存在着大量的可重用软件包,体量巨大。社区的热度促进了NPM的发展,也促进了Node.js的发展。但在NPM中发布一个新的包只需要注册一个NPM账户即可,更新一个包的新版本也只需要简单地进行注册表上传同步。恶意包在近几年成为一大焦点问题,因为哪怕官方很快地发现并清除了这些恶意包,在注册表中存活很短一段时间最终也会影响到一大片终端用户。
要从根本上解决这个问题,无非是从两个方面:一是阻断这些恶意包被同步到注册表中,即严格执行审查机制,在这些恶意包从上传开始到实际被同步到注册表中的这段时间里进行检查并清理;二是执行访问控制来限制包的安装过程,缩小攻击面。作者则是考虑在不改变现有的NPM基本过程的情况下,尽可能快地检测出恶意包,然后清理。(题外话,读者认为如此重要的一大社区生态,为了提高整体安全性做出一些改变是值得好好考虑的。
作者为了验证其方法在实际情况下的有效性,提出了三个准则:
作者提出了AMALFI来满足上述有效性准则:
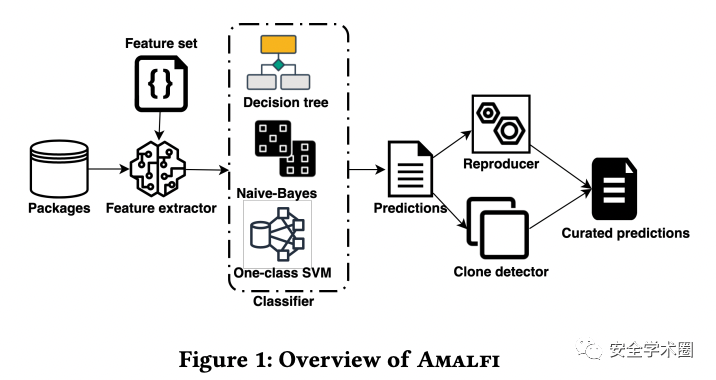
单包特征包括:
多版本特征包括:
需要说明的是,对于第一次上传到注册表中的包,作者引入了一个伪更新版本,设定版本发布之间的时间为0,更新类型则是单包特征中的描述。(题外话,作者并没有解释为何设定为0,读者存疑:难道不存在一个年久失修的包突然被攻击者接管的可能性么?
作者使用Tree-sitter来解析包中的Javascript和Typescript文件以获取单包特征:对于特征1,字符串匹配;对于特征2和特征3,API匹配;对于特征4,调用eval和Function来生成代码;对于特征5,考虑Shannon熵值。对于多版本特征则是利用npm view time获取版本发布时间间隔;利用语义分析获取更新类型。(作者未在文中给出相关启发式规则,感兴趣可以进一步去代码中看。
据读者先前的研究,NPM删除的包是不存在缓存的,也就是说没有任何途径再从官方的源中下载到。作者的恶意包是找NPM索取的。在索要到的643个恶意包的基础上,作者增加了1147个同一日期发布的正常包,构成了一个总量为1790的带标签语料库(题外话,这个语料库的量对于在当时单版本就有170w个包的总数据量是否有些小了,但在这个领域样本差距也是无可奈何的??
也正是为了解决样本的极度不平衡性,作者最后锁定了三个算法:决策树、朴素贝叶斯分类器和一分类SVM。决策树能很好地说明特征重要性,后两者主要是解决样本不平衡问题。文章中值得注意的是在训练一分类SVM时,作者设定v参的值为0.001,这个参数有点类似预期异常点(并不是verbose)。这意味1000个包的版本中存在着一个恶意版本。但实际上,作者描述到其在训练一分类SVM时使用的都是正常版本的包。关于这一点,读者在自己研究的时候也注意到了这一点,即预期异常概率的设定会严重影响到模型精确度,这里是值得好好考虑的一个点。(按作者的思路,哪怕训练使用的是全部正常的版本,也需要设定一个本不需要的预期异常概率。读者认为这里的做法的确不太合理,应当是按照比例投放几个已知恶意包满足预定比例,以此检查模型性能。
所谓reproducer就是指从源代码重新构建生成软件包。实际上,作者称碍于各种现实原因(没有源代码仓库、git提交记录对不上之类),很多正常的包也没办法还原生成,只能算作是一个效率不高的过滤器。clone detector主要是计算包内文件的md5值,并与已知恶意包的哈希值列表进行比较。考虑到包的具体情况不同,作者忽略了包名和版本。(题外话,读者认为首先reproducer效率有待改进,作为一个简单过滤器放在这里没有问题。但是这个clone detector只忽略了包名和版本,攻击者修改文件中涉及的IOCs或是随意调整编码不就能够绕过了么,这里的方法读者认为相当不严谨。
作者提出了AMALFI,这是一个用于检测恶意npm包的方法,包括了三个主要部件:一个在已知恶意包和正常包的样本上训练出的分类器;一个用于从源代码构建包的重构器;一个用于查找已知恶意包的检测器。
读者小结,该文提出的方法其实没有满足其在文章开始提到的三个准则。放弃人工审查并不能说明该方法表现更佳,就文章中表现出的种种,很难不相信这算一种掩耳盗铃的想法。分类器结合了各个算法的优点是很不错的思路,但本质上还是在做一个异常检测(一分类)问题,作者在设置一分类SVM参数时讲到其训练使用的都是正常版本的软件包(没有满足比例的恶意样本),但却将预期异常概率设定为0.001,这里逻辑上是说不通的。同时,唯二模型输出后的过滤器,一个not work well,一个取hash值时不严谨易被绕过。换句话说,过滤器没有起到相对有效的结果,那这个最终结果是否符合现实情况是需要打一个大大的问号的。
很赞哦! (119)

 网盾网络安全培训学校,课程内容紧跟互联网安全技术发展与企业实际用人需求,不断升级更新。
学员可以深入接触web安全基础、漏洞分析、安全测试、渗透测试等全栈解决方案,掌握网络安全分析及解决方案,成长为真正的网络安全人才。
网盾网络安全培训学校,课程内容紧跟互联网安全技术发展与企业实际用人需求,不断升级更新。
学员可以深入接触web安全基础、漏洞分析、安全测试、渗透测试等全栈解决方案,掌握网络安全分析及解决方案,成长为真正的网络安全人才。